%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Speech Synthesis

Easevoice Trainer
EaseVoice Trainer is a backend project designed to simplify and enhance the speech synthesis and conversion training process. This project is an improvement based on GPT-SoVITS, focusing on user experience and system maintainability. Its design philosophy differs from the original project, aiming to provide a more modular and customizable solution suitable for various scenarios, from small-scale experiments to large-scale production. This tool can help developers and researchers conduct speech synthesis and conversion research and development more efficiently.
Development & Tools
38.1K

Megatts 3
MegaTTS 3 is a highly efficient speech synthesis model based on PyTorch, developed by ByteDance, with ultra-high-quality speech cloning capabilities. Its lightweight architecture contains only 0.45B parameters, supports Chinese, English, and code switching, and can generate natural and fluent speech from input text. It is widely used in academic research and technological development.
Speech Recognition
38.9K
Openai.fm
OpenAI.fm is an interactive demonstration platform that allows developers to experience the latest text-to-speech models gpt-4o-transcribe, gpt-4o-mini-transcribe, and gpt-4o-mini-tts in the OpenAI API. This technology generates natural and fluent speech, making text content vivid and easy to understand. It is suitable for a variety of application scenarios, especially in voice assistants and content creation, helping developers better communicate with users and enhance user experience. This product is positioned for efficient speech synthesis and is suitable for developers who wish to integrate speech functions.
API Service
88.6K

Orpheus TTS
Orpheus TTS is an open-source text-to-speech system based on the Llama-3b model, aiming to provide more natural human speech synthesis. It boasts strong voice cloning and emotional expression capabilities, suitable for various real-time applications. This product is free and aims to provide developers and researchers with a convenient speech synthesis tool.
Text to Speech
199.5K
CSM 1B
CSM 1B is a speech generation model based on the Llama architecture, capable of generating RVQ audio codes from text and audio input. The model is primarily used in speech synthesis and boasts high-quality speech generation capabilities. Its advantages include the ability to handle multi-speaker dialogue scenarios and generate natural and fluent speech through contextual information. This open-source model is intended to support research and educational purposes but is explicitly prohibited from being used for impersonation, fraud, or illegal activities.
Speech Synthesis
235.7K
Fresh Picks
Sesame CSM
CSM is a conversational speech generation model developed by Sesame. It can generate high-quality speech from text and audio input. The model is based on the Llama architecture and uses the Mimi audio encoder. It is mainly used for speech synthesis and interactive voice applications, such as voice assistants and educational tools. The main advantages of CSM are its ability to generate natural and fluent speech and its ability to optimize speech output through contextual information. The model is currently open-source and suitable for research and educational purposes.
Speech Synthesis
153.5K
Sesame AI
Sesame AI represents the next generation of speech synthesis technology. By combining advanced artificial intelligence and natural language processing, it generates extremely realistic speech with authentic emotional expression and natural conversational flow. The platform excels at generating human-like speech patterns while maintaining consistent character traits, making it ideal for content creators, developers, and businesses to add natural voice capabilities to their applications. Its specific pricing and market positioning are currently unclear, but its powerful features and broad application scenarios give it high market competitiveness.
Speech-to-text
91.4K

Spark TTS
Spark-TTS is a highly efficient text-to-speech synthesis model based on large language models, featuring single-stream decoupled speech tokens. Leveraging the power of large language models, it directly reconstructs audio predicted from code, omitting the additional acoustic feature generation model, thus improving efficiency and reducing complexity. This model supports zero-shot text-to-speech synthesis, enabling cross-lingual and code-switching scenarios, making it ideal for speech synthesis applications requiring high naturalness and accuracy. It also supports virtual voice creation; users can generate different voices by adjusting parameters such as gender, pitch, and speaking rate. The model aims to address the inefficiencies and complexities of traditional speech synthesis systems, providing a highly efficient, flexible, and powerful solution for research and production. Currently, the model is primarily intended for academic research and legitimate applications such as personalized speech synthesis, assistive technologies, and language research.
Text to Speech
106.3K

Llasa
Llasa is a text-to-speech (TTS) base model based on the Llama framework, designed for large-scale speech synthesis tasks. The model is trained using 160,000 hours of tokenized speech data and has efficient language generation capabilities and multilingual support. Its main advantages include powerful speech synthesis capabilities, low inference costs, and flexible framework compatibility. This model is suitable for education, entertainment, and commercial scenarios, providing users with high-quality speech synthesis solutions. This model is currently freely available on Hugging Face, aiming to promote the development and application of speech synthesis technology.
Text to Speech
55.2K
English Picks
Octave TTS
Octave TTS is a next-generation speech synthesis model developed by Hume AI. It not only converts text to speech but also understands the semantics and emotions of the text to generate expressive speech output. The core advantage of this technology lies in its deep understanding of language, allowing it to generate natural and vivid speech based on context. It is suitable for various application scenarios, including audiobooks, virtual assistants, and expressive voice interaction. The emergence of Octave TTS marks the development of speech synthesis technology from simple text reading to a more expressive and interactive direction, providing users with a more personalized and emotional voice experience. Currently, this product is primarily aimed at developers and creators, providing services through APIs and platforms. Future expansion to more languages and application scenarios is expected.
Text to Speech
82.8K

Indextts
IndexTTS is a GPT-style text-to-speech (TTS) model primarily developed based on XTTS and Tortoise. It can correct Chinese pronunciation using pinyin and control pauses using punctuation marks. This system introduces a character-pinyin mixed modeling method in Chinese scenarios, significantly improving training stability, timbre similarity, and audio quality. Furthermore, it integrates BigVGAN2 to optimize audio quality. The model is trained on tens of thousands of hours of data and outperforms current popular TTS systems such as XTTS, CosyVoice2, and F5-TTS. IndexTTS is suitable for scenarios requiring high-quality speech synthesis, such as voice assistants and audiobooks, and its open-source nature makes it suitable for academic research and commercial applications.
Text to Speech
60.7K
Chinese Picks
Xingsheng AI
Xingsheng AI is a tool focused on generating AI podcasts. It utilizes advanced LLM models (such as Kimi) and TTS models (such as Minimax Speech-01-Turbo) to quickly transform text content into engaging podcasts. The primary advantage of this technology is its efficient content generation capability, which helps creators rapidly produce podcasts, saving time and effort. Xingsheng AI is suitable for content creators, podcast enthusiasts, and users who need to quickly generate audio content. Its focus is on providing users with a convenient podcast generation solution. Currently, there is no specific pricing information available.
Audio Production
77.3K
Llasa Training
LLaSA_training is a speech synthesis training project based on LLaMA, aimed at enhancing the efficiency and performance of speech synthesis models by optimizing training and inference computational resources. This project leverages both open-source datasets and proprietary datasets for training, supports various configurations and training methods, and offers high flexibility and scalability. Its main advantages include efficient data processing capabilities, strong speech synthesis effects, and support for multiple languages. This project is suitable for researchers and developers in need of high-performance speech synthesis solutions, applicable to the development of intelligent voice assistants, speech broadcasting systems, and other scenarios.
Model Training and Deployment
53.5K
Llasa 1B
Llasa-1B is a text-to-speech model developed by the Audio Lab at the Hong Kong University of Science and Technology. Based on the LLaMA architecture and integrated with speech tokens from the XCodec2 codec, it converts text into natural and fluent speech. The model has been trained on 250,000 hours of Chinese and English speech data and supports generating speech from plain text, as well as utilizing given voice prompts for synthesis. Its main advantage is the ability to produce high-quality multilingual speech, making it suitable for various applications such as audiobooks and voice assistants. The model is licensed under CC BY-NC-ND 4.0, prohibiting commercial use.
Text to Speech
82.2K
Llasa 3B
Llasa-3B is a powerful text-to-speech (TTS) model developed based on the LLaMA architecture, focused on Chinese and English speech synthesis. By integrating XCodec2's speech encoding technology, it efficiently converts text into natural and fluent speech. Its main advantages include high-quality speech output, support for multilingual synthesis, and flexible speech prompting capabilities. This model is suitable for various applications requiring speech synthesis, such as audiobook production and voice assistant development. Its open-source nature also allows developers to explore and expand its functionalities freely.
Text to Speech
104.3K
Kokoro Onnx
kokoro-onnx is a text-to-speech (TTS) project based on the Kokoro model and ONNX runtime. It supports English and plans to support French, Japanese, Korean, and Chinese. The model offers near real-time performance on macOS M1 and provides a variety of voice options, including whispering. The model is lightweight, approximately 300MB (around 80MB when quantized). This project is open-source on GitHub under the MIT license, facilitating easy integration and use for developers.
Text to Speech
144.1K
Kokoro 82M
Kokoro-82M is a text-to-speech (TTS) model created by hexgrad and hosted on Hugging Face. It features 82 million parameters and is open-sourced under the Apache 2.0 license. The model released version 0.19 on December 25, 2024, offering 10 unique voice packages. Kokoro-82M ranks first in the TTS Spaces Arena, showcasing its efficiency in parameter scale and data usage. It supports both American and British English, making it suitable for generating high-quality speech output.
Text to Speech
116.5K
Voxdazz
Voxdazz is an online platform that uses artificial intelligence technology to mimic celebrity voices. Users can select from a range of celebrity voice templates, input their desired text, and Voxdazz will generate corresponding videos. This technology is based on complex algorithms that replicate natural intonation, rhythm, and emphasis, making it very close to human speech. It is not only suitable for creating entertaining and humorous videos but also for sharing funny content that mimics celebrities. With its high-quality voice generation and user-friendly interface, Voxdazz provides users with a fresh avenue for entertainment and creative expression.
Speech-to-text
74.5K
English Picks
Gemini 2.0 Flash Experimental
Gemini 2.0 Flash Experimental is the latest AI model developed by Google DeepMind, designed to offer a low-latency and enhanced performance intelligent agent experience. This model supports native tool usage and is the first to natively create images and generate speech, marking significant advancements in AI technology's ability to understand and generate multimedia content. The Gemini Flash model family, with its efficient processing capabilities and broad range of applications, is a key technology driving the development of the AI field.
AI Model
67.6K
Cosyvoice Speech Generation Model 2.0 0.5B
CosyVoice Speech Generation Model 2.0-0.5B is a high-performance speech synthesis model that supports zero-shot and cross-language synthesis, enabling direct generation of speech output based on text content. Offered by Tongyi Laboratory, it boasts powerful speech synthesis capabilities and a wide range of applications, including but not limited to intelligent assistants, audiobooks, and virtual hosts. The model's significance lies in its ability to provide natural and fluent speech output, greatly enhancing the experience of human-machine interaction.
Text to Speech
72.3K
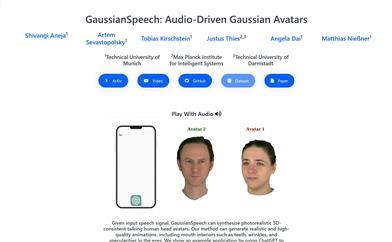
Gaussianspeech
GaussianSpeech is an innovative method capable of synthesizing high-fidelity animated sequences from speech signals to create realistic, personalized 3D head avatars. The technology combines speech signals with 3D Gaussian drawing techniques to capture human head expressions and detailed movements, including skin wrinkling and finer facial motions. Key advantages of GaussianSpeech include real-time rendering speed, natural visual dynamics, and the ability to exhibit a variety of facial expressions and styles. The underlying technology involves the creation of large-scale, multi-view audio-visual sequence datasets and the development of audio conditional transformation models that can directly extract lip and expression features from audio input.
Video Production
47.2K
Outetts 0.2 500M
OuteTTS-0.2-500M is a text-to-speech synthesis model built on Qwen-2.5-0.5B. It has been trained on a larger dataset, achieving significant improvements in accuracy, naturalness, vocabulary range, voice cloning capability, and multilingual support. Special thanks to Hugging Face for the GPU funding that supported this model's training.
Speech Synthesis
103.8K
Outetts
OuteTTS is an experimental text-to-speech model that generates speech using pure language modeling techniques. Its significance lies in harnessing advanced language modeling technology to transform text into natural-sounding speech, which is crucial for applications like speech synthesis, voice assistants, and automated dubbing. Developed by OuteAI, it supports both Hugging Face and GGUF models and offers advanced features such as voice cloning through the interface.
Text to Speech
92.2K
Soundstorm
SoundStorm is an audio generation technology developed by Google Research that significantly reduces the time needed for audio synthesis by generating audio tokens in parallel. This technology can produce high-quality audio that maintains high consistency with speech and acoustic conditions, and can be integrated with text-to-semantic models to control the speech content, speaker voice, and speaking turns, facilitating long-text speech synthesis and the generation of natural dialogues. The significance of SoundStorm lies in its ability to tackle the slow inference speed issues faced by traditional autoregressive audio generation models when processing long sequences, thereby enhancing both the efficiency and quality of audio generation.
Audio Generation
57.4K
Maskgct TTS Demo
MaskGCT TTS Demo is a text-to-speech (TTS) demonstration based on the MaskGCT model, provided by amphion on the Hugging Face platform. This model utilizes deep learning technology to convert text into natural and fluent speech, suitable for various languages and scenarios. The MaskGCT model has garnered attention for its efficient speech synthesis capabilities and support for multiple languages. It not only enhances the accuracy of speech recognition and synthesis but also offers personalized voice services across different applications. Currently, this product is available for free trial on the Hugging Face platform, with further pricing and positioning information to be explored.
Text to Speech
144.3K
GLM 4 Voice
GLM-4-Voice is an end-to-end voice model developed by a team from Tsinghua University, capable of directly understanding and generating Chinese and English speech for real-time dialogue. Leveraging advanced speech recognition and synthesis technologies, it achieves seamless conversion from speech to text and back to speech, boasting low latency and high conversational intelligence. The model is optimized for intellectual engagement and expressive synthesis capabilities in the voice modality, making it suitable for scenarios requiring real-time voice interaction.
Speech Recognition
61.0K

Llama 3.2 3b Voice
Llama 3.2 3b Voice is a voice synthesis model available on the Hugging Face platform that converts text into natural and fluent speech. This model utilizes advanced deep learning techniques to mimic human speech intonation, rhythm, and emotion, making it suitable for various applications such as voice assistants, audiobooks, and automated announcements.
AI Speech Synthesis
90.0K
VALL E 2
VALL-E 2 is a voice synthesis model introduced by Microsoft Research Asia, significantly enhancing the robustness and naturalness of speech synthesis through repetition-aware sampling and grouped coding modeling techniques. This model can convert written text into natural speech, applicable across multiple domains including education, entertainment, and multilingual communication, playing a crucial role in improving accessibility and enhancing cross-language communication.
Text to Speech
65.1K
Fresh Picks

Deepgram Voice Agent API
The Deepgram Voice Agent API is a unified voice-to-voice API that enables natural-sounding conversations between humans and machines. This API is backed by industry-leading speech recognition and synthesis models that allow for natural and real-time listening, thinking, and speaking. Deepgram is committed to advancing a voice-first AI future through its agent API, integrating cutting-edge generative AI technology to create business solutions with smooth, human-like speech agents.
AI speech recognition
61.8K
Chinese Picks
Iflytek Virtual Human
iFlytek Virtual Human utilizes cutting-edge AI virtual image technology combined with core AI technologies such as speech recognition, semantic understanding, speech synthesis, NLP, and the Spark large model to provide virtual human asset construction, AI-driven services, and multi-modal interaction across various scenarios. It offers one-stop production of audio and video content, making creative processes flexible and efficient; enter text or audio in the virtual 'AI studio,' with rendering completed in under 3 minutes.
AI Color Generation
66.5K
- 1
- 2
- 3
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.0K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.4K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
41.7K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
42.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.4K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.0K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.1K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M